Introduction
This project for TAMBR aims to change how audio tracks are chosen and matched with video
content. The goal is to create an easy-to-use tool that automatically analyzes textual input to
determine the mood of a video and suggest audio tracks that fit that mood. This tool seeks to
streamline the audio-video editing process, making it more efficient and accessible for
content creators.
This project enhances the creative industries by using advanced NLP to automate mood
detection and audio matching from text input. It saves time for creators, boosts productivity,
and helps video editors and marketers find suitable music, ensuring engaging and effective
content for viewers.
I, began experimenting with AI-driven object detection (YOLO) for sound alignment in video
creation. After testing prototypes and thorough onboarding, feedback revealed object
detection alone is insufficient for music recommendation without associated emotions. I
shifted to NLP models for mood detection, using text input with autocomplete to improve
soundtrack suggestions.
To achieve this, I, developed two content-based recommendation engines using NLP
techniques. One engine uses the TF-IDF approach, and the other uses an embedding model
called Word2Vec. These engines help analyze the text and recommend audio tracks that best
match the video's mood.
Here, I will also showcase my first experimented object detection prototype
and how I discovered a workable solution.
Objectives
The Word2Vec model captures semantic word relationships to enhance mood detection in
text, improving audio recommendations for emotional coherence in video content. By analyzing keywords like "happy" and "energetic," it suggests contextually relevant tracks such
as "Summer Vibes," ensuring efficient and accurate audio selection for video editors.
The TF-IDF (Term Frequency - Inverse Document Frequency) model simplifies finding the
right music for videos by processing user-input keywords like "happy" or "melancholic." It
compares these with music metadata to calculate similarity scores, recommending the most
relevant tracks. This saves video editors time and ensures the music matches the video's
mood.

Advantages
TF-IDFexcels with short text inputs like video titles, ensuring accurate mood detection and
relevant audio recommendations. It's user-friendly, interpretable, and computationally
efficient, suitable for real-time applications. TF-IDF highlights key mood-related terms,
leading to precise mood detection and improved audio recommendations.
Word2Vec converts words into dense numerical vectors, capturing semantic relationships
and contextual meanings. It enables precise mood-based audio recommendations from
simple keywords to complex descriptions, enhancing machine comprehension of text. This
makes Word2Vec invaluable for effective text analysis tasks
Combined Benefits & Potential Impact
TF-IDF and Word2Vec excel in text feature extraction. TF-IDF assigns weights based on term importance, while Word2Vec reduces dimensionality, enhancing accuracy and speed. Their integration improves text classification, training time, and recommendation systems, making NLP models more efficient for web and mobile applications.
DATA
The NLP models use a CSV dataset of music track metadata:
- TITLE: The title of the music track.
- ARTIST: The artist who performed the music track.
- TOP GENRE: The primary genre classification of the music track.
- SUB GENRE: A more specific genre classification within the top genre.
- BPM: Beats per minute, indicating the tempo of the music track.
- ENERGY LEVEL: A measure of the track's intensity and activity.
- DANCEABILITY: Indicates how suitable the track is for dancing, based on tempo, rhythm stability, and beat strength.
- LOUDNESS: The overall volume level of the track in decibels.
- VALENCE: A measure of the track's musical positiveness, with higher values indicating more positive emotions.
- ACOUSTICNESS: A measure of the track's acoustic quality, with higher values indicating more acoustic sounds.
- KEY: The musical key in which the track is composed.
- UNIVERSAL GENRES: Broader genre classifications that encompass multiple specific genres.
- ADVANCED MOODS: Detailed descriptions of the emotions conveyed by the music track.
- BRAND VALUES: Keywords representing the values and qualities associated with the music track, often for branding purposes.
- AUGMENTED KEYWORDS: Additional descriptive keywords that provide more context about the music track.
- BASIC MOODS: General mood descriptors of the music track, providing a broad emotional classification.
DATA PRE-PROCESSING STEPS
- Loaded the Data: The dataset is loaded from a CSV file using pandas.
- Selecting Relevant Columns: Only specific columns relevant to mood and keyword analysis are retained. These columns are 'TITLE', 'ARTIST', 'ADVANCED MOODS', 'BRAND VALUES', 'UNIVERSAL GENRES', 'AUGMENTED KEYWORDS', and 'BASIC MOODS'.
- Combining keywords for Analysis: A new column, 'combined_keywords', is created by concatenating the text from 'ADVANCED MOODS', 'BRAND VALUES', 'AUGMENTED KEYWORDS', and 'BASIC MOODS'. This column is used to generate TF-IDF vectors and Word2Vec embeddings.
- Keyword extraction for TF-IDF: Counted the occurrences of each word in a document and measure how common or rare a word is across all documents. Multiply TF and IDF values to get the TF-IDF score for each word.
- Generating TF-IDF Vectors: The 'combined_keywords' column is vectorized using the TF-IDF approach. The TF-IDF vectors represent the importance of each word in the context of the entire dataset.
- Keyword Categorization: Identified the top N Keywords with the highest TF-IDF scores. Manually group similar keywords based on their TF-IDF scores and context used.
- Keyword Extraction or Generating Word2Vec Embeddings: Using a pre-trained spaCy model '(en_core_web_md)', embeddings for the 'combined_keywords' are generated. Each keyword's vector representation captures its semantic meaning and context.
- Keyword Categorization: Using cosine similarity scores between word vectors. Calculating the cosine of the angle between pairs of word vectors to determine their similarity. Group keywords with high cosine similarity scores into the same category (Krasňanská et al., 2021).
- Handling Missing Values: Any missing values in the 'combined_keywords' column are handled, ensuring that the data is clean and ready for analysis.
TECHNICAL DETAILS
Python: Primary language used for developing recommender system.
Frameworks & Libraries:
- Pandas: For data manipulation and analysis.
- Scikit-learn: For implementing the TF-IDF vectorizer and cosine similarity calculations.
- ipywidgets: For creating interactive widgets in Jupyter Notebooks.
- IPython.display: For displaying the widgets.
- NumPy: For numerical operations and handling vector data.
- SpaCy: For natural language processing tasks, such as text embedding in the Word2Vec model.
ALGORITHM EXPLANATION
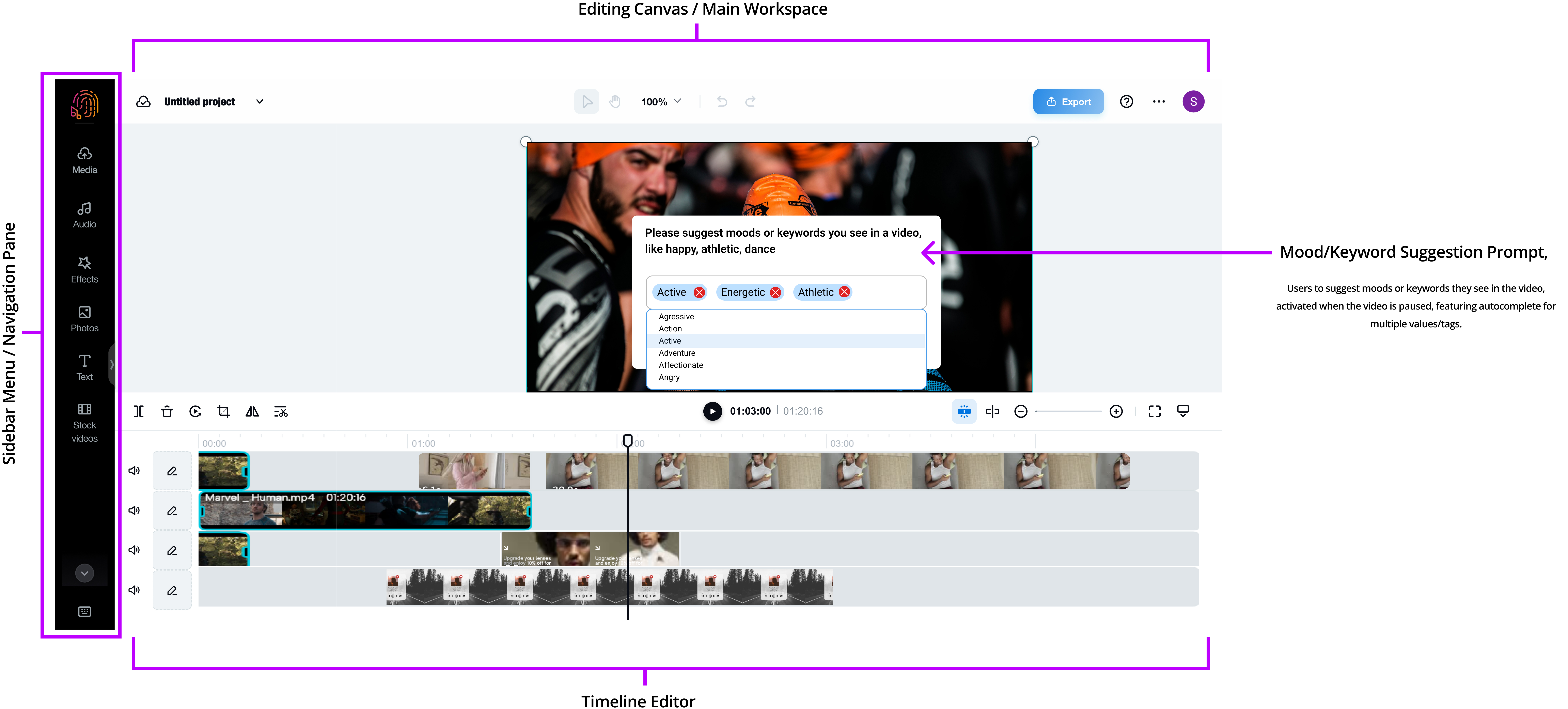
1. User Interface (UI) Frontend Process Flow:

2. Back-End Process:

3. Human-in-the-loop:
Users can enter keywords that describe the mood or theme they want for their video
content. The system uses TF-IDF and Word2Vec models to suggest audio tracks that match
these keywords. Users receive recommendations with relevance percentages, preview
the tracks, and save the ones they like.
The feedback helps refine the recommendations by adjusting the weight of certain
keywords, during autocomplete suggestions, and similarity in thresholds. By selecting and
refining keywords based on user input, the models can better understand the context and
extract relevant keywords or context based on the mood observed in video content.
The system retrains the TF-IDF and Word2Vec models using the updated feedback data
to improve accuracy. Keywords and their associations are refined continuously.
Performance metrics are monitored to ensure ongoing improvements.
This data-driven feedback loop helps the system get better over time, making audio
recommendations more accurate and relevant. By integrating user feedback, the system
aligns better with user preferences and the mood of their video content, enhancing user
experience and recommendation effectiveness.
4. A brief overview of experimental Object Detection Model:
My previous research focused on 'AI-Driven Object Detection and Recommended Sound Alignment in Video Content Creation.' However, feedback indicated that this approach lacked emotional connection for music recommendations. Additionally, the EU AI Act restricts emotion recognition in certain contexts (Artificial Intelligence Act: MEPs Adopt Landmark Law | News | European Parliament, 13 C.E.), prompting me to shift to NLP models for mood detection via text analysis. My idea was to link object detection with a content-based music recommendation system by using extracted object features as input. These features act as descriptors or keywords for the video content. Integrating these object features into the recommendation algorithm ensures that the suggested music aligns well with the video's context.


Performance Metrics
1. TF-IDF MODEL
Cosine Similarity Scores:
The system calculates the cosine similarity between TF-IDF vectors of input keywords and
metadata of music tracks. Recommendations are made based on the highest similarity scores,
showing how well the input keywords match the track metadata. The effectiveness of the TFIDF
model depends on the richness and specificity of the keyword metadata. Higher cosine
similarity scores suggest better matches.
The accuracy of the TF-IDF model can be further improved by enriching metadata with more
detailed and accurate descriptions can enhance the accuracy of recommendations.
Additionally, allowing users to input more specific and relevant keywords can also improve
the precision of the model.
2. WORD2VEC MODEL
Cosine Similarity Scores:
The Word2Vec model calculates similarity scores based on word embeddings, which
encapsulate semantic relationships between words. Recommendations are made based on
the highest similarity scores, offering contextually relevant matches even if the exact
keywords are not present in the metadata. The model’s strength lies in its ability to
understand and match words semantically, providing more contextually relevant
recommendations.
Continuously refining the metadata and input keywords can enhance the model’s accuracy,
and ensuring that the recommendation system remains robust and contextually relevant by
updating the semantic context within the word embeddings.
Code
The code for Keyword-Based Mood Audio Matching in Video Content is available on Github.
Future Work & Conclusion
Future iterations will transform the current prototype into a fully functional audio-video
editing tool. This tool will feature keyword selection from an autocomplete suggestion list and
allow users to adjust keyword weights in an input field. Refining keywords based on the
video's mood will enhance recommendation relevance. Future enhancements may include
integrating additional data types, such as audio features (e.g., pitch, tempo) and visual cues
from video content, to improve recommendations further.
Incorporating historical user interaction data, like listening history, will enable more
personalized recommendations. Advanced embedding techniques like BERT could capture
deeper contextual relationships between words and phrases, while sentiment analysis can
better understand the emotional tone of input keywords and match it with music moods.
Providing users with more detailed feedback options (e.g., specific aspects of the music they
liked or disliked) will help in fine model tuning. Insights into how different keywords and
features influence recommendations will help users refine their inputs for better results.
Analyzing the impact of mood-based recommendations on long-term user engagement and
satisfaction will be essential.
Implementing these enhancements and exploring new applications will significantly improve
the accuracy, relevance, and user satisfaction of Word2Vec and TF-IDF based
recommendation systems.
